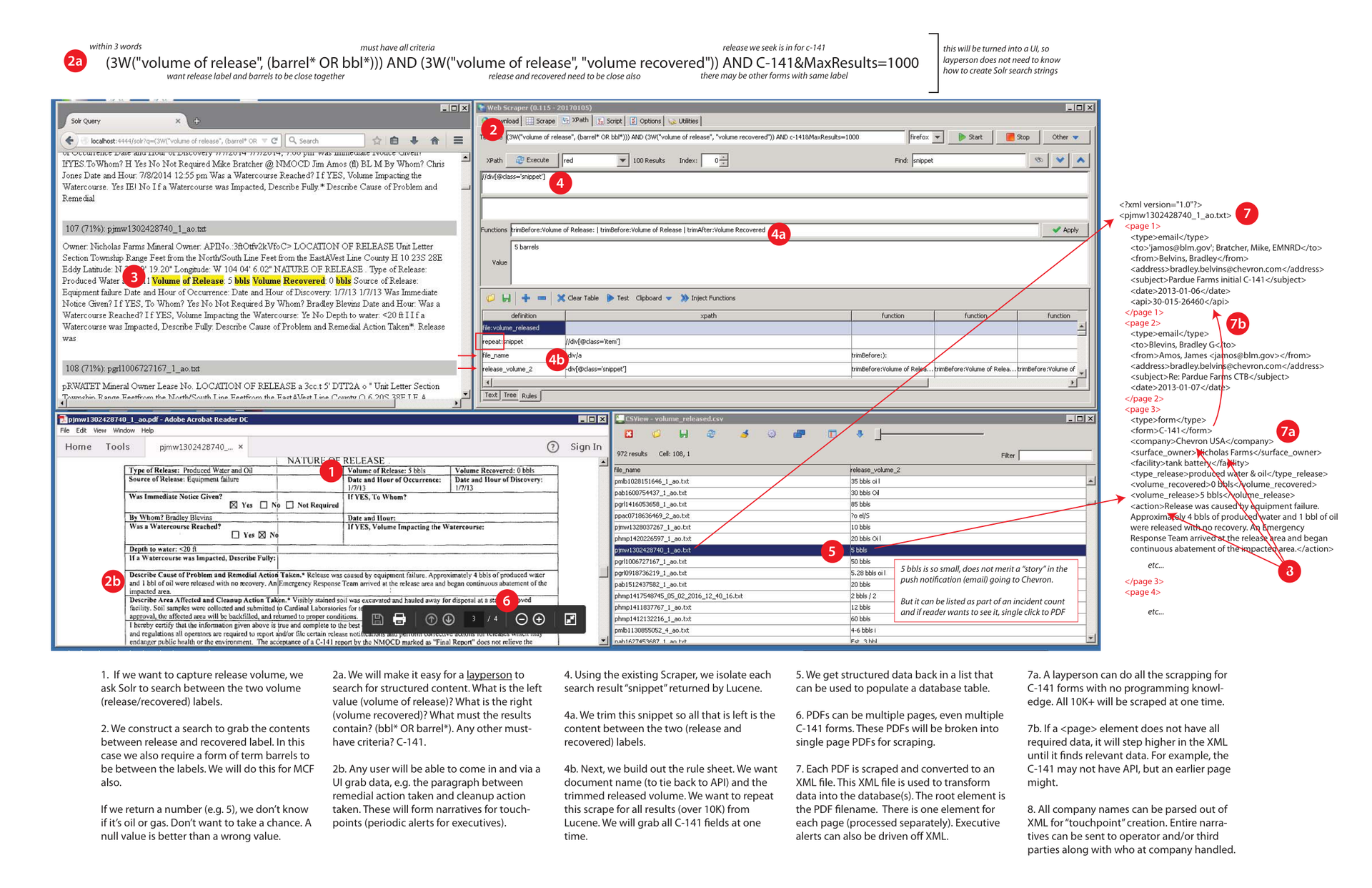
Automated Document Harvesting:
This technical workflow demonstrates how complex, unstructured PDF reports can be automatically parsed and scraped into highly structured XML and CSV formats. By automating the extraction of key variables like spill volumes, organizations can eliminate tedious manual data entry, reduce human error, and accelerate processing times across thousands of legacy regulatory documents.
|
Precision Semantic Querying:
Utilizing advanced Solr search strings and proximity queries allows the system to accurately locate vital statistics embedded deep within block text. By scanning for terms like volume released or recovered within close proximity, the scraper isolates critical metrics from noise, ensuring that even complex, multi-page compliance filings yield high-fidelity, actionable business intelligence.
|
Actionable Operational Alerts:
Translating raw PDF data into structured databases enables real-time reporting, operator benchmarking, and instant executive alerts. High-impact incidents can automatically trigger email notifications to key stakeholders, while minor events are quietly logged for trend analysis, allowing management to maintain absolute environmental compliance oversight while focusing resources on high-priority operational risks.
|