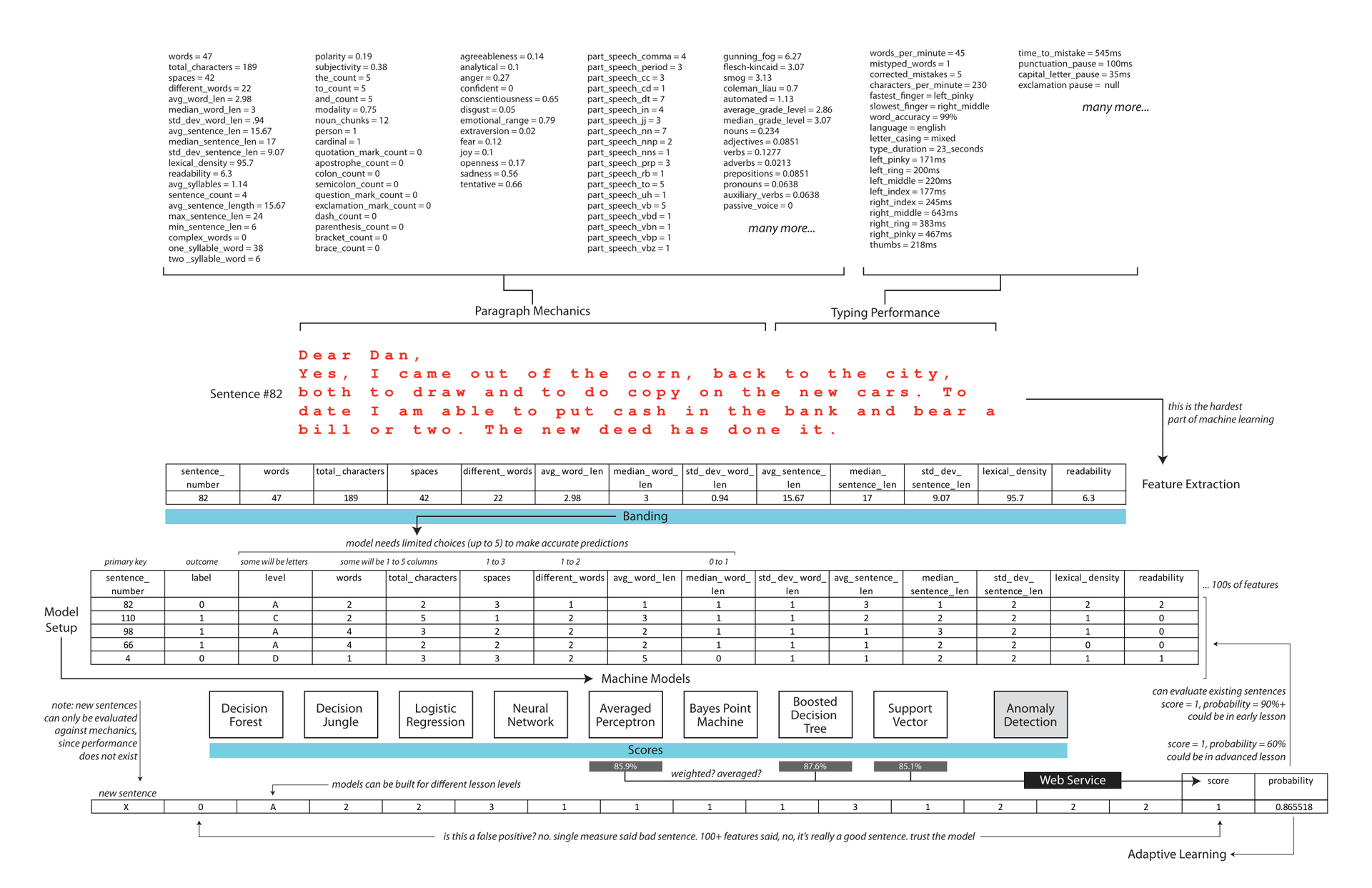
Multidimensional Feature Extraction:
The pipeline begins by capturing highly granular, multi-dimensional user inputs. It extracts complex paragraph mechanics—such as readability indices, linguistic structures, and emotional sentiment—alongside physical typing performance data, including keypress speeds and finger pauses. This comprehensive feature extraction converts raw text and behavioral biometrics into a rich dataset ready for advanced downstream analytical modeling.
|
Ensemble Modeling & Banding:
To process this diverse data, continuous features undergo banding to discretize variables and simplify prediction patterns. The structured data is then processed through an ensemble of diverse machine learning algorithms, including Decision Forests, Neural Networks, and Support Vector Machines. By aggregating multiple models, the system optimizes prediction accuracy for lesson levels and ensures reliable classification.
|
Real-Time Adaptive Feedback:
Finally, the system deploys these ensemble predictions via a real-time web service to score new entries instantly. It incorporates an intelligent adaptive learning feedback loop that continuously refines model accuracy. By evaluating over one hundred simultaneous features, the network effectively eliminates false positives, dynamically calibrating lesson difficulty to match individual user capability over time.
|