Automating Perforation Selection:
The core hypothesis proposes using machine learning models to analyze LAS files for automated perforation zone selection. By training algorithms on engineer-selected labels, this technology aims to identify hydrocarbon presence, optimize existing wellbore performance, and completely replace manual log reading. Ultimately, this shifts the entire process from human operators to highly efficient, computer-driven recommendations.
|
Unlocking Subsurface Big Data:
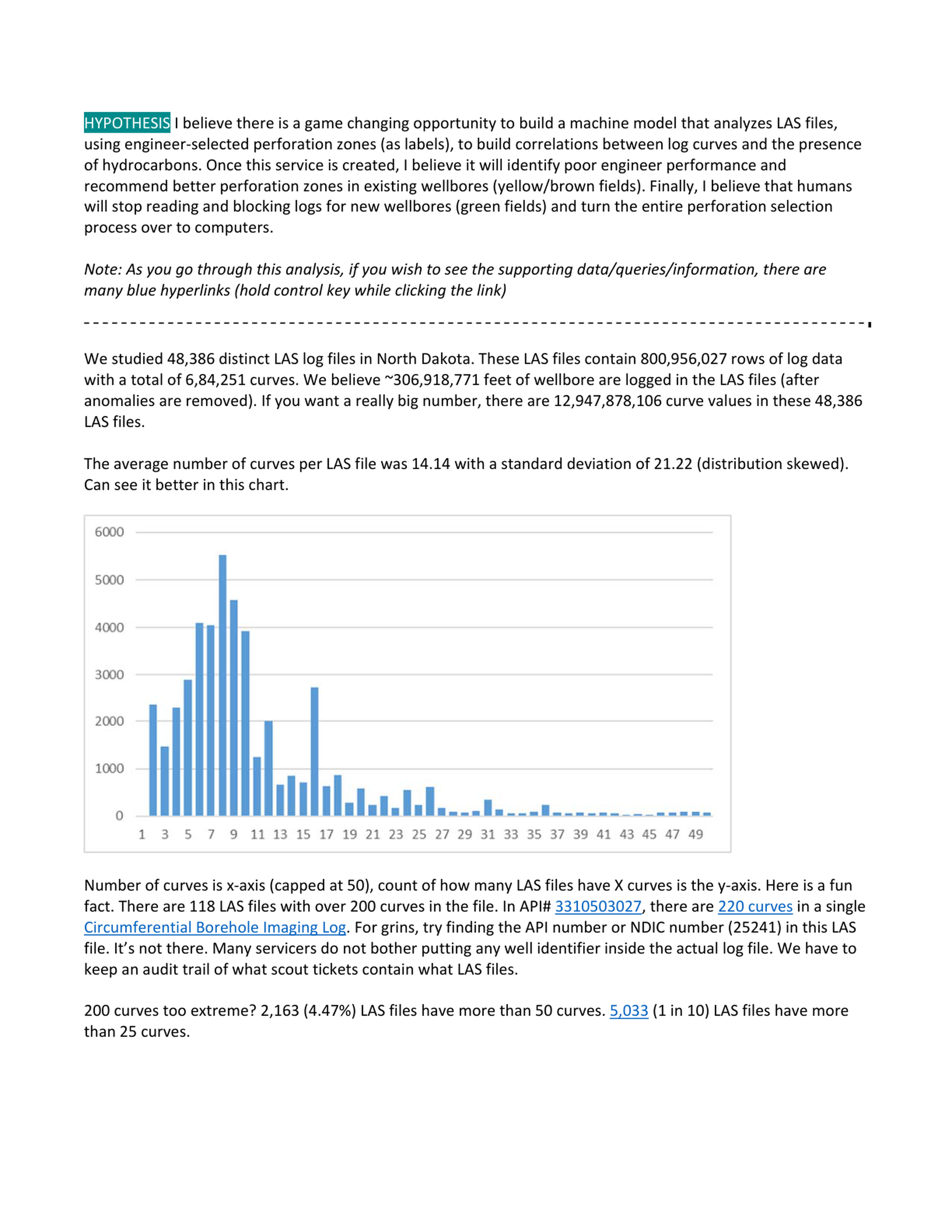
This analysis leverages a massive regional dataset consisting of over 48,000 distinct LAS log files from North Dakota. Containing more than 800 million rows of data, nearly seven million curves, and billions of individual data points, this extensive database provides the robust foundation necessary to train accurate, highly reliable predictive algorithms for subsurface exploration.
|
Addressing Integration Challenges:
Significant challenges exist within the raw data, including massive variance in curve distribution and missing critical well identifiers like API numbers inside actual log files. Managing these inconsistencies requires maintaining detailed audit trails using scout tickets. Overcoming these integration obstacles is vital to clean the dataset before training machine learning models for production environments.
|