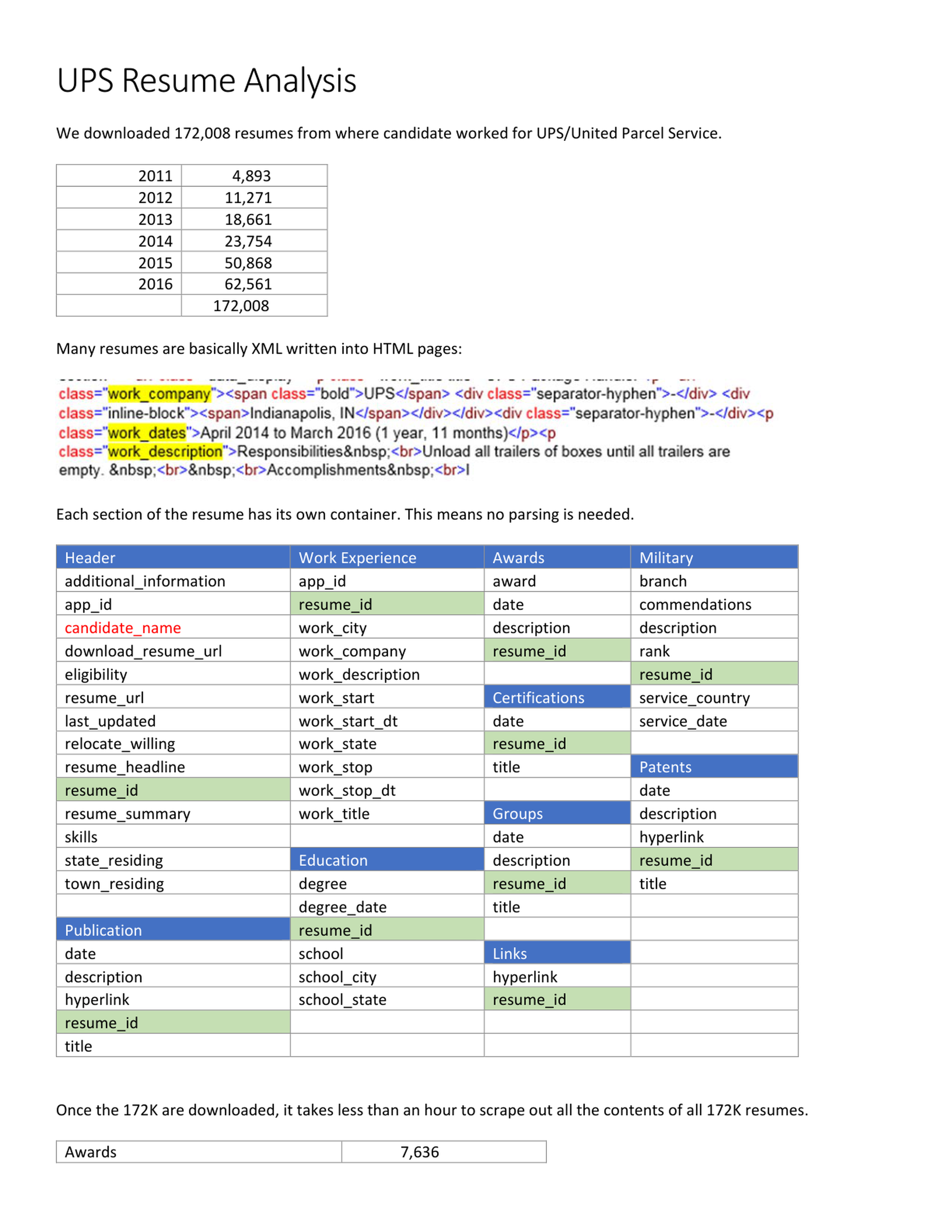
Exponential Candidate Data Scale:
This analysis details the strategic acquisition of 172,008 resumes from candidates with history at UPS. Collected over a six-year period from 2011 to 2016, the data pool experienced massive exponential growth, culminating in over 62,000 resumes in the final year alone, providing a deep, robust dataset for comprehensive talent acquisition trends and competitive organizational intelligence.
|
Structured Containerized Schema Architecture:
Rather than dealing with chaotic unstructured documents, these resumes leverage highly organized XML embedded within HTML pages. Because every crucial data section is strictly containerized, complex custom parsing is completely eliminated. The relational schema seamlessly maps resume elements from work experience and certifications to military history utilizing a shared unique identifier for unified, consistent dataset integration.
|
Rapid Scale Processing Performance:
The technological capability demonstrated is remarkably efficient, processing all 172,008 raw records in under an hour once the HTML source is fully downloaded. This rapid scraping velocity yields immediate analytical capability. Crucial metrics, such as identifying the 7,636 documented awards, can be instantly extracted, showcasing the incredible speed, scalability, and operational feasibility of this big-data pipeline.
|