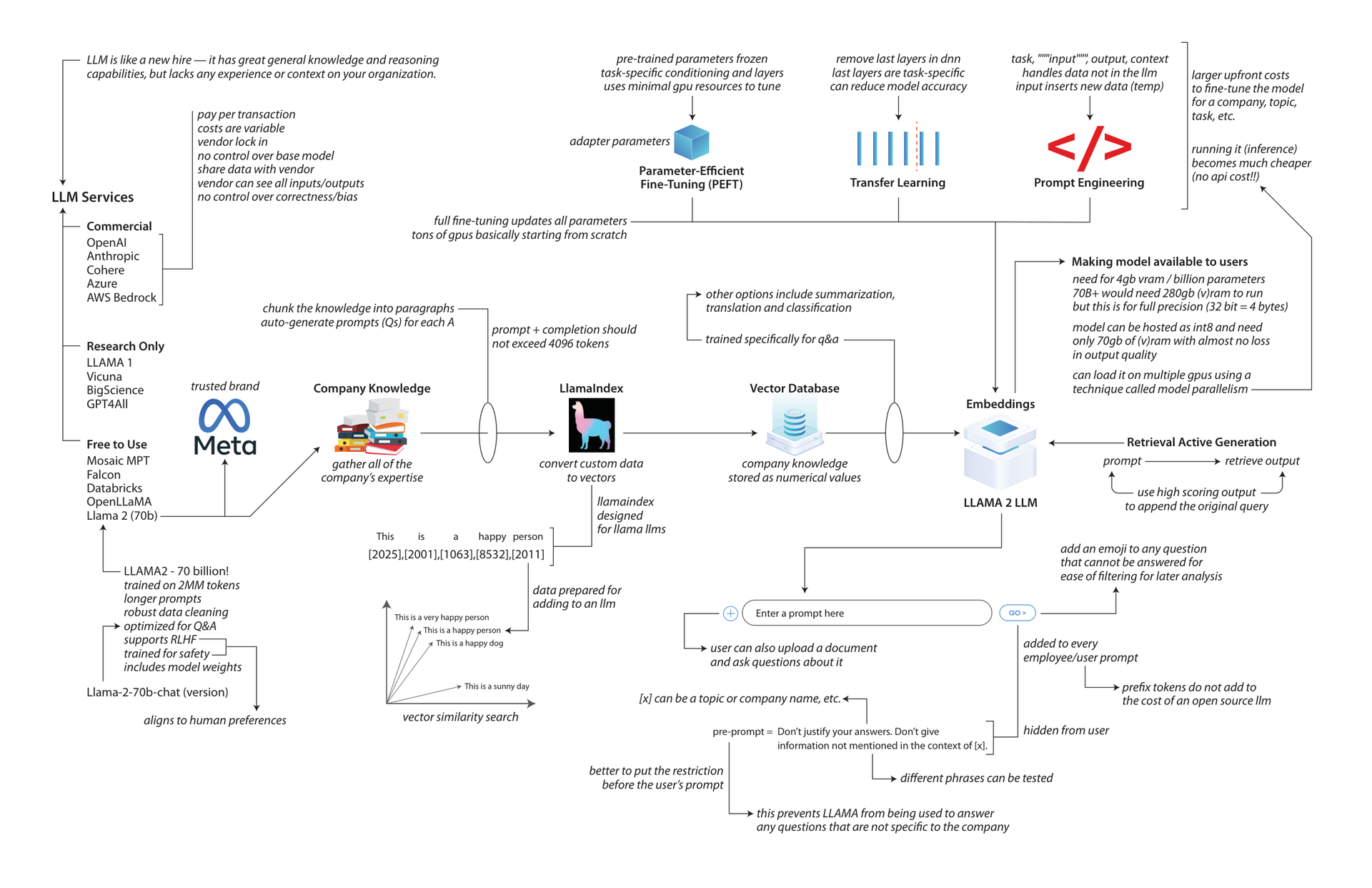
Strategic Model Selection:
Organizations must choose between commercial LLM APIs and open-source models like LLaMA 2. While commercial services offer ease of use, they introduce challenges like variable transaction costs, vendor lock-in, and data privacy risks. Conversely, self-hosting open-source alternatives ensures complete control over sensitive enterprise data and eliminates recurring API fees, despite higher upfront setup requirements.
|
RAG-Driven Knowledge Integration:
Integrating proprietary company knowledge requires structured pipelines rather than complete model retraining. By processing unstructured corporate data into paragraph chunks, tools like LlamaIndex convert information into numerical vector embeddings. Stored securely within a centralized vector database, this data enables semantic similarity searches that dynamically augment user prompts, ensuring highly accurate and context-aware model responses.
|
Efficient Optimization & Scaling:
Maximizing operational efficiency requires balancing computational costs against model accuracy. Techniques like parameter-efficient fine-tuning and transfer learning allow targeted model adaptation with minimal processor resources. Furthermore, model optimization through low-precision quantization significantly reduces hardware requirements, enabling enterprises to deploy large-scale open-source systems locally or across multiple clustered chips without sacrificing inference quality.
|